Machine Learning Essentials: The Ultimate Guide to Classification and Clustering
Topics Covered
1. Introduction
2. Classification
— What is Classification?
— Types of Classification
— How Classification Works
— Real-World Examples of Classification Algorithms3. Clustering
— What is Clustering?
— Types of Clustering Algorithms
— How Clustering Works
— Real-World Examples of Clustering Algorithms
— Which clustering technique should I use?4. Difference Between Classification and Clustering
5. Conclusion
Introduction
Classification and clustering are two essential machine learning techniques used to categorize data. However, they differ in their approach. Classification is used to assign data points to predefined classes, while clustering is used to group data points together based on their similarity.
Classification and clustering are used in a wide variety of applications. For example, classification algorithms can be used to filter spam emails, detect fraudulent transactions, and diagnose diseases. Clustering algorithms can be used to segment customers, segment images, group text documents together, and group genes together.
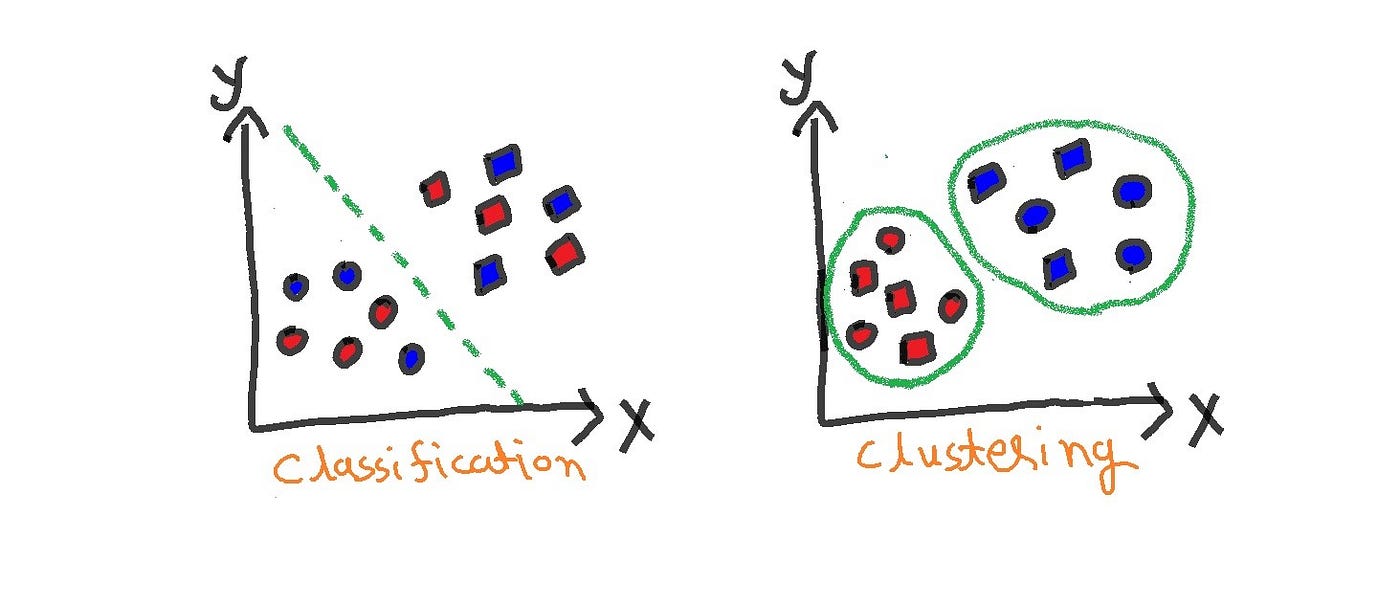
What is Classification?
Classification is a supervised learning technique, which means that it requires a labeled training dataset to learn the relationship between the features and the class labels. Once the classifier is trained, it can be used to predict the class label of new, unseen data points.
There are two main types of classification tasks: binary classification and multiclass classification.
- Binary classification tasks involve classifying data into exactly two classes. A classic example of binary classification is spam filtering, where emails are classified as spam or not spam. Other examples of binary classification tasks include fraud detection (fraudulent or not fraudulent) and medical diagnosis (cancerous or not cancerous).
- Multiclass classification tasks involve classifying data into more than two classes. For example, an image classification algorithm might be trained to classify images into different categories, such as cats, dogs, and cars. Other examples of multiclass classification tasks include text classification (news article, blog post, social media post) and product recommendation (clothing, electronics, home goods).
How Classification Works?
Classification algorithms work by learning patterns in the data. These patterns are associated with each predefined class. Once the algorithm has learned these patterns, it can be used to predict the class of new, unseen data points.
For example, a spam filter might learn that emails with certain keywords or phrases are more likely to be spam. Once the spam filter has learned these patterns, it can be used to predict whether a new email is likely to be spam or not.
Real-World Examples of Classification
- Spam filtering — Classifying emails as spam or not spam
- Fraud detection — Classifying transactions as fraudulent or not fraudulent
- Medical diagnosis — Classifying a patient’s condition as a particular disease or not
- Product recommendation — Recommending products to customers based on their past purchase history
- Customer segmentation — Classifying customers into different segments based on their demographics and purchase behavior
Some of the most common classification algorithms include: Logistic regression, Decision trees, Random forests, Support vector machines, Naive Bayes
some algorithms can be used for both binary and multiclass classification. For example, logistic regression, decision trees, and random forests can be used for both binary and multiclass classification. However, other algorithms are specifically designed for binary or multiclass classification. For example, SVMs are typically used for binary classification, while neural networks are typically used for multiclass classification.
What is Clustering?
Clustering is an unsupervised learning technique, which means that it does not require labeled data. Clustering algorithms group data points together based on their similarity, without the need for predefined class labels.
There are four main types of clustering algorithms: centroid-based clustering, density-based clustering, distribution-based clustering, and hierarchical clustering.
- Centroid-based clustering algorithms partition the data into a predefined number of clusters. The clusters are defined by their centroids, which are the average values of the data points in each cluster. The K-means algorithm is the most popular centroid-based clustering algorithm.

K-means works by randomly initializing a set of centroids. Then, each data point is assigned to the cluster with the closest centroid. The centroids are then updated to be the average values of the data points in each cluster. This process is repeated until the centroids no longer change.
- Density-based clustering algorithms group data points together based on their density. The clusters are defined by regions of high data point density. These algorithms are able to handle noise and outliers in the data more effectively than centroid-based clustering algorithms.

The DBSCAN algorithm is a popular density-based clustering algorithm. DBSCAN works by identifying core points, which are data points that have a certain number of neighbors within a certain distance. A cluster is then defined as all of the data points that are reachable from the core points.
- Distribution-based clustering: Distribution-based clustering algorithms group data points together based on the underlying probability distributions of the data. These algorithms assume that the data is composed of a mixture of probability distributions, and they attempt to identify the parameters of these distributions. Once the parameters of the distributions have been identified, each data point can be assigned to the distribution that it is most likely to belong to.
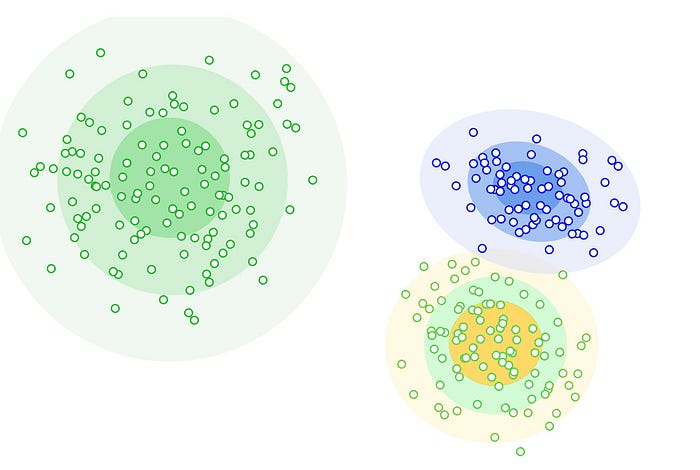
The Gaussian Mixture Model (GMM) is a popular distribution-based clustering algorithm. GMMs assume that the data is a mixture of Gaussian distributions. The algorithm attempts to identify the parameters of the Gaussian distributions and then assign each data point to the Gaussian distribution that it is most likely to belong to.
- Hierarchical clustering is a type of connectivity-based clustering algorithm. This means that it groups data points together based on how close they are to each other, or how similar they are to each other.

Hierarchical clustering can be either agglomerative or divisive. Agglomerative algorithms start with each data point in its own cluster and then iteratively merge the most similar clusters together. Divisive algorithms start with all of the data points in a single cluster and then iteratively split the cluster into smaller and smaller clusters.
Hierarchical clustering algorithms produce a dendrogram, which is a tree-like diagram that shows how the clusters are related to each other.
How Clustering Works?
Clustering algorithms work by learning patterns in the data and grouping similar data points together. These patterns are not associated with any predefined classes, but rather with the similarity between the data points themselves. Once the algorithm has learned these patterns, it can be used to group new, unseen data points into clusters based on their similarity to the existing clusters.
For example, a customer segmentation algorithm might learn that customers who purchase similar products tend to be in the same cluster. The algorithm might also learn that customers who spend similar amounts of money tend to be in the same cluster. Once the clustering algorithm has learned these patterns, it can be used to group new customers into clusters based on their purchase behavior.
Real-World Examples of Clustering
- Image segmentation — Grouping pixels in an image into different segments, such as objects, background, and foreground
- Text clustering — Grouping text documents into different clusters based on their content
- Anomaly detection — Identifying data points that are anomalous or unusual, such as fraudulent transactions or network intrusions
Which clustering technique should I use?
The best clustering algorithm to use depends on the specific application and the nature of the data. If the data is well-defined and there is a clear separation between the clusters, then a centroid-based clustering algorithm, such as K-means, may be a good choice. If the data is noisy or there are outliers, then a density-based clustering algorithm, such as DBSCAN, may be a better choice. If the data is complex and there is no clear separation between the clusters, then a distribution-based clustering algorithm, such as a GMM, may be a better choice. Hierarchical clustering algorithms can be used in a variety of applications, including exploratory data analysis, feature engineering, and anomaly detection. However, hierarchical clustering algorithms can be computationally expensive, especially for large datasets.
Difference Between Classification and Clustering

Conclusion
Classification and clustering are two powerful machine learning techniques that can be used to solve a wide variety of problems. Classification is used to categorize data into predefined classes, while clustering is used to group data points together based on their similarity.
I hope you’ve gained a clear understanding of the Classification and Clustering Algorithms. Feel free to share your thoughts or connect with me on LinkedIn to continue the conversation.
